体育游戏app平台来挖掘“智能”而非“系统”的鸿沟-开云官网切尔西赞助商(2025已更新(最新/官方/入口)
发布日期:2025-09-06 09:08 点击次数:211

开始:新智元体育游戏app平台
【新智元导读】刚刚,全新AI基准测试器用xbench出身,通过双轨评估体系和长青评估机制,追踪模子才调与实质场景价值。
跟着基础模子的快速发展和AI Agent进入规模化应用阶段,被庸碌使用的基准测试(Benchmark)却濒临一个日益机敏的问题:想要真确地反应AI的客不雅才调正变得越来越弯曲。
因此,构建愈加科学、长效和确乎反应AI客不雅才调的评测体系,正在成为涵养AI时代突破与产物迭代的紧要需求。

有鉴于此,红杉中国今天庄重推出一款全新的AI基准测试器用xbench,并发布论文《xbench: Tracking Agents Productivity ,Scaling with Profession-Aligned Real-world Evaluations》。
在评估和推动AI系统提高才调上限与时代鸿沟的同期,xbench会重心量化AI系统在真确场景的效率价值,并接纳长青评估的机制,去捕捉Agent产物的弊端突破。(点击文末【阅读原文】即可下载阅读本论文,建议使用电脑端进行下载)

https://xbench.org/files/xbench_profession_v2.4.pdf

摘记
xbench接纳双轨评估体系,构建多维度测评数据集,旨在同期追踪模子的表面才调上限与Agent的实质落地价值。该体系改造性地将评测任务分为两条互补的干线:(1)评估AI系统的才调上限与时代鸿沟;(2)量化AI系统在真确场景的效率价值(utility value)。其中,后者需要动态对王人实践全国的应用需求,基于实质责任经过和具体社会扮装,为各垂直领域构建具有明确业务价值的测评圭臬。
xbench接纳长青评估(Evergreen Evalution)机制,通过合手续爱戴并动态更新测试内容,以确保时效性和筹备性。咱们将如期测评市集主流Agent产物,追踪模子才调演进,捕捉Agent产物迭代过程中的弊端突破,进而预测下一个Agent应用的时代-市集契合点(TMF,Tech-Market Fit)。看成孤独第三方,咱们死力于于为每类产物假想公允的评估环境,提供客不雅且可复现的评价休止。
首期发布包含两个中枢评估集:科学问题解答测评集(xbench-ScienceQA)与中语互联网深度搜索测评集(xbench-DeepSearch),并对该领域主要产物进行了抽象排行。同期建议了垂直领域智能体的评测方法论,并构建了面向招聘(Recruitment)和营销(Marketing)领域的垂类Agent评测框架。评测休止和方法论可通过xbench.org网站及时查抄。
在夙昔两年多的时分里,xbench一直是红杉中国在里面使用的追踪和评估基础模子才调的器用,今天咱们将其公开并孝敬给统统这个词AI社区。不管你是基础模子和Agent的开采者, 照旧筹备领域的人人和企业,或者是对AI评测具有浓厚兴味的究诘者,咱们都宽贷你加入,成为使用并完善xbench的一份子,一齐打造评估AI才调的新范式。
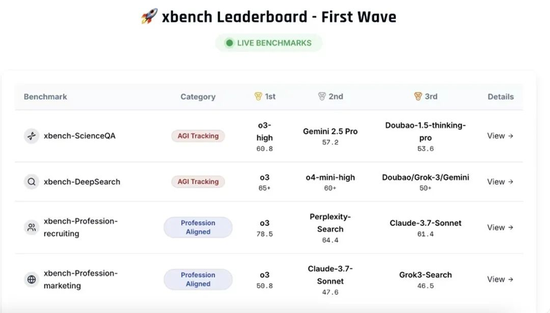 xbench Dual-track Leaderboard 2025.05
xbench Dual-track Leaderboard 2025.05
为什么当今需要新的Eval系统
2022年ChatGPT推出后,红杉中国开动对AGI程度和主流模子实行每个月的评测与里面报告。
2023年3月,咱们开动种植xbench的第一批额外题库,题目类型主要针对Chatbot简便问答及逻辑念念考,如:
· 香蕉的宽泛根是若干?
· 小明应承成为最奏效的投资东谈主,经过一番勤勉,最终他奏效了。求教用什么成语描述这个情况相比允洽?
咱们见证了主流模子从20-30分,在18个月内,提高到90-100分。2024年10月,咱们第二次相比大规模地更新了xbench题库,换掉了统统模子都得满分的题,新题主要针对Chatbot复杂问答及推理,以及简便的模子外部器用调用才调(tool use),如:
· 设 f(x) 是一个奇函数,而 g(x) 是一个偶函数。那么, f(f(g(f(g(f(x)))))) 是奇函数、偶函数照旧都不是?
· Q :将 /nt 目次下统统允洽 ‘result_*.txt’ 步地的文献,按 * 数字从小到大的律例,合并到一个文献中。何况定名为 ‘results_total.txt’ 。
咱们再次见证了主流模子的跳跃,这一次的速率更快,主流模子在6个月内“刷爆”了咱们的第二期题库。
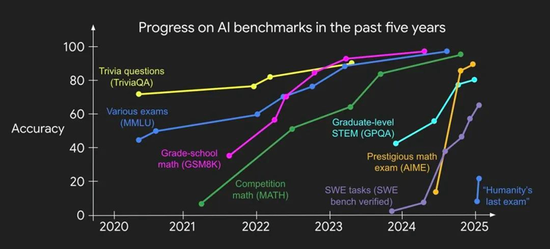 评估的灵验时分在急剧缩小(图源:姚顺雨个东谈主博客)
评估的灵验时分在急剧缩小(图源:姚顺雨个东谈主博客)
2025年3月,咱们开动第三次对xbench题库进行升级,但这一次,咱们开动停驻来质疑现存评估状貌,念念考两个中枢问题:
1. 模子才融合AI实质效率之间的关系:咱们出越来越难的题目意旨是什么,是否落入了惯性念念维?AI落地的实质经济价值竟然和AI会作念难题正筹备吗?举个例子,步调职责任的utility value很高,但AI作念起来跳跃至极快,而“去工地搬砖”这么的责任AI却简直无法完成。
2. 不同期间维度上的才调相比:每一次xbench换题,咱们便失去了对AI才调的前后可比性追踪,因为在新的题集下,模子版块也在迭代,咱们无法相比不同期间维度上的单个模子的才调怎样变化。在判断创业样式的时候,咱们心爱看创业者的“成长斜率”,但在评估AI才调这件事上,咱们却因为题库的束缚更新而无法灵验判断。
接下来咱们应该怎样作念评估?
为了玩忽上述两个中枢问题,咱们垂危需要构建新的评估平台,并重心面向:
■ 冲破惯性念念维,为实践全国的实用性开采新颖的任务成立和评估状貌
以‘Search’才调为例,AI才调评估集的进化旅途可能是:
Single-turn QA→Search→Deep Search(Multi-step reasoning)→Deeper Search(Multi-hop or Chained Reasoning)
要是咱们跳脱出“究诘视角”惯性,转向“市集与业务视角”,任务和环境的种种性会爆炸式增长,Search类的题就会变成:
→Marketing→KOL Search→‘一家智能投影仪品牌策画在中东市集进行内容投放,主见东谈主群为 35 岁以下、有孤茕居住空间的科技早期用户,主要通过生涯状貌类博主触达。 AI Agent 需完成: ① 在中英文多平台上识别优质创作家,判断其内容调性是否迫临 ‘ 居家文娱 + 智能家居 ’ ; ② 预测不同地区(如迪拜与利雅得)的 CTR 各异; ③ 缓助完成组合推选。’→$6,000 (东谈主工完成该任务需 3 名中东腹地营销东谈主员,约耗时 1 周,总本钱约 $6,000 ( $2,000/ 东谈主 / 周))
→Recruiting→People Search→‘一家头部 VC 因循的多模态大模子初创公司,正在寻找一位 ‘ 具备高质料开源样式教授、熟悉 transformer 架构、曾在 FAIR 或 DeepMind 实习 / 合作过 ’ 的 AI 工程负责东谈主。主见候选东谈主不一定在招聘平台上活跃,大部分信息散播在 GitHub 、 arXiv 、 X (原 Twitter )、国外社区论坛中。 AI Agent 需完成: ① 跨平台搜索与团员; ② 候选东谈主配景重建(进修、样式、实习); ③ 对时代契合度自动评分; ④ 生成 Cold outreach 政策邮件草稿。’→¥9,000 (东谈主工完成该任务,频频需1名高档猎头 +1名时代究诘员,耗时约 1 周,东谈主力总本钱约 ¥9,000 )
下半场的评估,不仅需要越来越难的AI Search才调的查考基准(AI Capabilities Evals),也需要一套对王人实践全国人人的实用性任务体系(Utility Tasks)。
前者查考的是才调鸿沟,呈现是Score,此后者查考的是实用性任务和环境种种性、买卖KPIs(conversion rate、closing rate)和胜仗的经济产出。
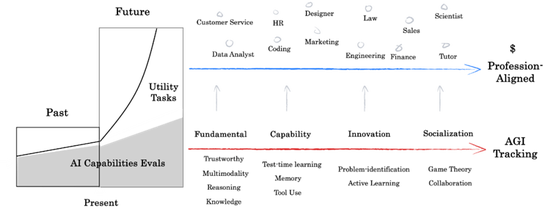
咱们引入Profession Aligned的基准见识,咱们以为接下来的评估会分为AGI tracking与Profession Aligned,AI将濒临更多复杂环境下效率的查考,从业务中网罗的动态题集,而不只是更难的身手题。
■ 建树长青评估体系
静态评估集一朝面世,会出现题目流露导致过拟合然后赶紧失效的问题。咱们将爱戴一个动态更新的题目推行评估集来缓解这一气候。
针对AI Capacity Evals:学术界建议了好多出色的方法论,然而受限于资源与时分不充分,无法爱戴成动态推行的合手续评估。咱们但愿能延续一系列公开评估集的方法,并提供第三方、瑕瑜盒、Live的评测。
针对Profession Aligned Evals:咱们但愿建树从真确业务中Live网罗机制,邀请各行业的办事人人与咱们共同构建和爱戴行业的动态评估集。
同期,在动态更新的基础上,咱们假想可横向对比的才调目的,用于在时分上不雅察到排行除外发展速率与弊端突破的信号,匡助咱们判断某个模子是否达到市集可落地阈值,以及在什么时分点上,Agent不错给与已有的业务经过,提供规模化办事。
面向真确全国的动态评估,
Live Evaluations for Agents
Agent评测的双轨旅途
咱们推出xbench双轨系列评估集,分为xbench-AGI Tracking与xbench-Profession Aligned。咱们将AGI Tracking评测视为Agent应用落地的基础台阶,而Profession Centric评测则是对接真确出产场景的高阶实践。
AGI track评测旨在考证模子在特定才调维度上是否从0到1具备了智能理会,这类评测的弊端是要填塞难和玄机、填塞有区分度,来挖掘“智能”而非“系统”的鸿沟。只消当某个AI弊端才调在AGI Tracking中收尾从0到1的突破,才可能进一步解锁更多专科责任经过,进入Profession Aligned评测的鸿沟。
Profession Aligned评测则聚焦于实践出产场景,是把Agent当成一个数字职工放在具体业务经过里来进行查考。其评估中枢并非智能存在与否,而是在真确场景下的录用休止和买卖价值。
Profession Aligned不错有好多类型应用来处罚,评估不会休止处罚决策,只会考查休止。另外,Profession Aligned评估从对出产力的需求启程,是界说垂类应用/寻找垂类AI处罚决策,即使这个场景应用还莫得作念出来。
以营销和东谈主力资源场景为例,咱们通过对xbench AGI track中xbench-DeepSearch评测目的追踪,以为AI search这一弊端模子才调正在快速熟识,寻找简历、分析候选东谈主匹配度,在各大平台上寻找KOL、分析KOL与需求的匹配度,都是潜在AI能收尾的责任流。于是咱们开动构建xbench-Profession-Recruitment及xbench-Profession-Marketing但愿对王人Agent业务落地价值,预测TMF的时分点。
在AI Search除外,跟着AI弊端才调可料到的拓展至多模态默契和生成,营销素材的出产和投放会被纳入可能达到TMF的设施-进入Profession Aligned评估的测试范围内。
同样,应用于recruiting时,senior recruiter的责任流不局限于people search、people evaluation,更难的在于对候选东谈主永久爱戴和换取以致是薪酬谈判和达成交游设施——这里AI具备永久挂牵、竞争和决策博弈等中枢职能,亦然下一个阶段弊端智能的突破标的,咱们会合手续监测弊端才调突破并增多Profession-Aligned测评的丰富度。
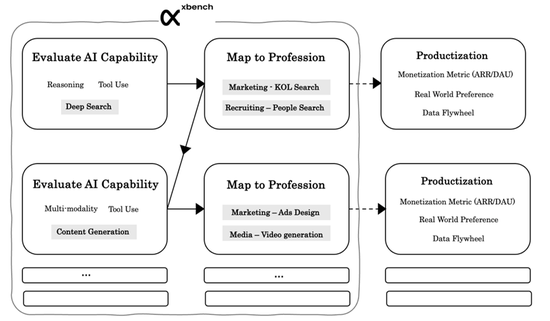
以AI弊端才调为中心的评估(AGI Tracking)
2023-2024年大模子在学问、多模态、挂牵、请示盲从与推理才调上取得显耀突破,这些突破的积贮变成了Agent应用才调的爆发——但仍然在永久挂牵、真实度、问题发现、多智能体协调与博弈才调等上存在短板。
咱们但愿收拢AI尚未充分处罚的中枢才调,构建并合手续爱戴对应的评估集。
咱们服气针对这些弊端才调,学术界建议了好多出色的方法论,然而受限于资源与时分不充分,无法爱戴成合手续评测、动态推行的评估。咱们但愿能延续一系列公开评估集的方法,并提供第三方、瑕瑜盒、Live的评测。
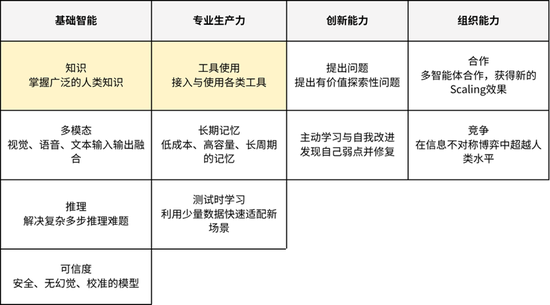
咱们把Agent才调拆分红基础智能、专科实践才调、改造才调与组织才调,每个层级中咱们会拆分出组成收尾AGI的弊端要素。
AI的发展不一定是从基础到高阶的律例进行,咱们不错料到的是,在AI获取了组织才调后一经存在基础真实度的问题。
这一次咱们发布的xbench-ScienceQA与xbench-DeepSearch评估属于Knowledge与Tool Use的子类别,测试Agent在这两项主才调分类下的子任务才调。后续咱们会围绕这些弊端问题合手续发布新的评估,并追踪市面产物的理会。
■ xbench-ScienceQA: 查考基础智能-学问
该评测集用于测试究诘生水平的学科学问和推理才调。咱们网罗可靠、多领域、高等进修难度、搜索引擎上清苦的、谜底明确的高质料题目数据。
已有的筹备评估集如GPQA、SuperGPQA等取得了很大认同与存眷,但他们均为一次性发布,清苦如期更新的机制。无法灵验检验评估集流露的程度。
咱们但愿种植出一个按照季度更新的ScienceQA题目数据,并每月合手续报告最新模子的才调理会,每季度更新一次。
咱们邀请来自顶级院校的博士究诘生以及资深行业人人出题,并接纳LLM难度检修、搜索引擎检修、同业检修等状貌确保题目的自制性、区分度与正确性。
■ xbench-DeepSearch :查考专科出产力-器用使用
自主诡计(Planning)→信息网罗(Search)→推理分析(Reasoning)→转头归纳(Summarization)的深度搜索才调是AI Agents通向AGI的中枢才调之一,也给评估带来了更难的挑战。
基于简便事实的评估集如SimpleQA、Chinese SimpleQA八成评估信息网罗才调,但清苦对自主诡计和推理分析才调的查考;基于前沿科学的评估集如HLE、AIME擅长查考模子的推理分析才调,但弱于自主诡计和信息网罗才调的度量。
为了更好的查考Agents的深度搜索才调,咱们推出并开源了xbench-DeepSearch评测集,具备以下特色:
• 得当中语互联网环境,遏抑搜索信息源对休止的影响;
• 难度高,条目Agent具备诡计+搜索+推理+转头的端到端抽象才调;
• 统统题目经由东谈主工出题并交叉考证,保证题目的新颖性,谜底的正确性和独一性,便捷自动化评测;
• 合手续更新,每月合手续报告最新模子的才调理会,每季度更新一次评估集。
咱们以为2025年咱们会见证AI更多在基础智能与专科出产力上的进展,本年咱们的后续评估中会存眷:
1. 具有念念维链的多模态模子能否生成商用水平视频?(多模态,推理,器用使用)
2. MCP 器用大面积使用是否具有真实度问题?(器用使用,真实度)
3. GUI Agents 能否灵验使用动态更新 / 未进修的应用?(器用使用,测试时学习)
以专科责任为中心的评估(Profession Aligned)
追求与真确全国任务对王人是咫尺AI评估的中枢诉求,这里咱们建议以专科责任为中心的构建方法。
已有的真确全国评估频频所以AI才调为中心,去庸碌地掩盖不同场景与领域,这关于携带通用模子的迭代至极有价值。
关联词Agent应用频频需要处罚垂类场景任务,并针对垂类需求进行定制假想,此时通用评估休止的参考价值下落。
咱们看到在Coding、客服与医疗领域出现高质料的评估,并带动了对应专科Agent才调的快速演进与产物化。专科中心的评估会快速在更多领域延张开,其占主流AI评估的比重也会快速提高。
面向专科责任的评估是但愿从特定办事人人启程,分析它自己的责任流与念念维模式,构建出与人人举止对王人的任务、实施环境与考证状貌,经过如下图所示:
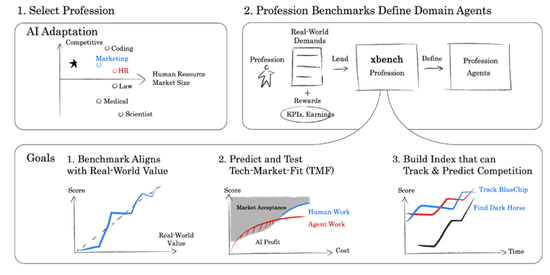
xbench Profession Aligned的构建盲从如下三条中枢原则:
• 评估由需求界说:针对一个办事构建评估集,优先梳理其业务经过与任务分类,聚焦于可评估的任务项。关于部分暂不可评估的任务,通过模拟状貌转动为可评估体式。
• 评估任务随时分逐步产生的从人人业务中Live网罗:任务并非“出题”生成,而是在人人日常业务中徐徐积贮与网罗。关于动态变化的任务,咱们合手续从真确业务流中获取与市集最迫临的评估内容。
• 领域价值驱动评估主见:每项任务标注人人完成所需时分,并趋奉薪资基准估算任务的经济价值。每个任务预设TMF主见,一朝Agent达标则住手更新,Profession-Aligned的评估难度追务实质匹配,而不是合手续变难。
这里咱们以招聘人人为例,假想xbench-Profession-Recruitment。
咱们通过与多家头部猎头企业合作,梳理人人每周责任在不同任务上的时分分派。并让人人对这些任务的紧要性进行评估,筛选出领域责任的拆分图谱。
底下是一个结构化的责任任务拆解和经济价值的对王人,以及对任务在现阶段可收尾性和可评测性的梳理:
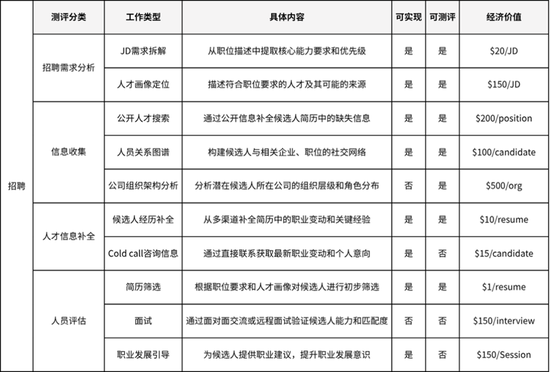
在每个单项任务中,咱们从现存时代角度分析其可测性与可行性。第一期xbench-Profession-Recruitment收录了JD需求拆解、东谈主才画像定位、候选东谈主履历补全、东谈主物关系默契、公开东谈主才搜索等几类任务。
咱们与专科猎头公司,以及具有充分历史业务数据积贮的营销企业分别共建了xbench-Profession-Recruitment与xbench-Profession-Marketing这两个评估任务。不错点击文末【阅读原文】,在论文中看到更多休止。
咱们会以实质出产力需求为起点,通过上述方法论,集合行业人人拆解专科责任经过形成任务,界说客不雅、可复现的评价目的,一一构建Profession Aligned的评估集,先于垂类应用界说出才调主见,用eval携带profession agent的落地。
瞻望将连接拓展至金融(Finance)、法律(Law)、销售(Sales)等高价值专科领域的评估任务体系构建。咱们宽贷来自筹备领域的人人学者、产业企业、究诘机构参与共建,共同鞭策Profession-Aligned Eval的发展。
长青评估(Evergreen Eval)
评估有人命周期的任务与产物
静态评估集中出现题目流露的问题。如LiveBench与LiveCodeBench评估的出现,欺诈动态更新的题目推行评估集,缓解了题目流露的问题,关联词,在Agent应用的评估任务中仍有新挑战。
领先,Agent应用的产物版块是具有人命周期的。Agent产物的迭代速率很快,会束缚集成与开采新功能,而旧版块Agent可能会被下线。咱们天然不错在褪色时分测试同类Agent不同产物的才调,然而不可相比不同期间的产物才调跳跃。
同期,Agent战争的外部环境亦然动态变化的。即使是同样的题目,要是解题需要使用互联网应用等内容快速更新的器用,在不同期间测试后果不同。

上述表格展示了针对Agent的Live评测可获取的休止。欺诈该休止不错得到同期不同产物的排行,然而由于评估环境与任务的调节,不同期评测之间的才调增长是莫得捕捉到的。因此咱们但愿处罚如下问题:
评估集与模子束缚迭代情况下,假想目的追踪Agent才调的合手续增长。
统计上,咱们不错针对残败得分矩阵揣测每个Agent版块的才调主因素。咱们接纳样式反应表面(Item Response Theory, IRT)完成对Agent Capability的揣测。IRT表面把被测对象才调θ,题目难度b以及题目区分度α按照如下模子建模,被测对象在测试题目上的得分为:
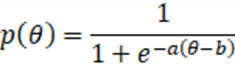
这个公式得意题目得分概率p是[0,1]之间的取值,更大的难度整个b会遏抑得分概率,而强的才调整个θ则会提高得分概率。关于区分度α更大的题目,频频奉陪才调θ增长愈加疲塌,意味题目能区分更庸碌才调的评测对象。
咱们使用OpenCompass动态更新的评估休止来考证IRT方法(https://rank.opencompass.org.cn/leaderboard-llm/?m=25-01)。
该榜单从2024年2月开动,每隔1-3个月更新一次题库并发布评估休止,底下左图展示了不同模子在评估时分评测的得分,同样系列模子被褪色激情的线进行不绝。天然榜单休止很好知道了每次评估时模子才调排序,但因为题目更新,不同期间模子得分时不具有可对比性。
而欺诈IRT揣测的才调得分,则不错很好地体现模子才调合手续增长的趋势。咱们不错不雅察到2024年10月之后Google Gemini模子才调的快速跟进,以及Deepseek v2与r1发布所带来的两次通晓提高。

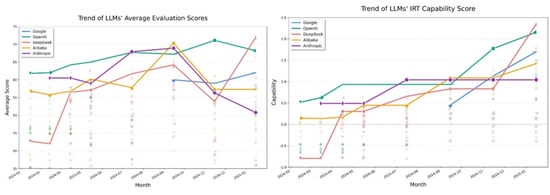
在后续的Agent评估中,咱们会合手续报告Agent评估集不同产物的IRT才调得分,用于在时分上不雅察到排行除外发展速率与弊端突破的信号。
评估Agent的时代市集匹配(Tech-Market Fit)
本钱亦然Agent应用落地的决定性因素之一。
Inference Scaling让模子与Agent不错通过干预更多推理算力来取得更好的后果。这种干预既不错来自于强化学习带来的更长念念维链,也不错是在念念维链的基础上引入更屡次数的推理与汇总进一步提高后果。
关联词咱们在实践任务中需要探讨Inference Scaling带来的干预产出比,找到在破耗、蔓延与后果上的均衡。雷同于ARC-AGI,咱们会追求为每个评估集报告在后果-本钱图上的需求弧线、东谈主类才调弧线以及现存产物的最优供给弧线。
在Benchmark的得分-本钱图上,咱们不错辞别出左上区域的市集接受区与右下的时代可行区。东谈主力本钱应当是市集接受区边际的一部分。左图展示了时代尚未落地的现象,而中间图展示了TMF后的现象,而其中交叉部分是AI带来的增量价值。关于具有TMF的AI场景,东谈主力资源应当更多干预在领域的前沿以及不可评估的任务,何况市集会因为东谈主力资源与AI算力的稀缺性不同重新给东谈主类孝敬的价值订价。
咱们以为每个专科领域会履历3个阶段:
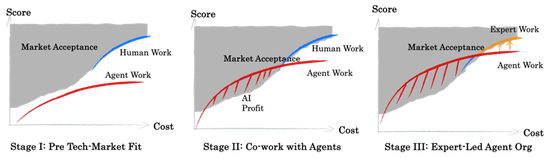
1. 未达成TMF:时代真实与市集接受区域莫得错杂,此时Agent应用仅是器用或见识,无法录用休止或规模化产生价值;Agent对东谈主的影响较小。
2. Agent与Human共同责任:时代真实与市集接受区域发生错杂,交叉区域是AI带来的价值增量,包括(1)以低于最低东谈主类本钱提供可行办事,(2)匡助提高玩忽重迭性、质料条目中等的责任内容。而高水准的责任内容,由于数据稀缺、难度更高、一经需要东谈主来实施,此时由于稀缺性,企业获取的AI Profit可能会被用于支付高端责任产出。
3. 专科化Agent:领域人人在构建评估体系,并涵养Agent迭代。人人的责任从录用休止转向构建专科评估进修垂类Agents,并提供规模化办事。
其中从1.向2.的调遣是由AI时代突破、算力与数据的Scaling带来的,而2.转向3.的进展依赖于熟悉垂类需求、圭臬、历史教授的人人。
此外,在部分领域中,AI可能带来新的得意需求的状貌,改变已有的业务经过和出产关系组成状貌。
AI可能会带来价值调动、改变东谈主力需求的结构,咱们服气社会会因为更高效的出产效率与买卖模式增多东谈主类的总体福利。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
包袱剪辑:何俊熹 体育游戏app平台